
词法分析——词法单元和正则表达式
本系列文章是《编译原理》的读书笔记,并加入了一些个人的理解。本系列的主要内容顺序如下:
1)、首先解释什么是词法单元;
2)、如何手动识别词法单元;
3)、最后是词法分析器如何自动机自动识别词法单元;
本文主要是看一下词分析器的词法单元部分。包括一些基本概念,以及词法单元的识别。
首先我们先大体上看一下词法分析器的作用。它的主要任务是读入源程序的输入字符、将它们组成词素,生成并输出一个词法单元的序列。每个词法单元对应一个词素。
这里我们有提到几个专业名词:词素、词法单元。它们的定义马上就会说到,我们可以先看看下面这幅图:
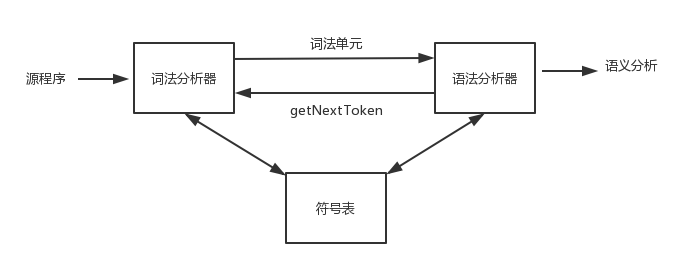
从图中我们可以看出来词法分析器还在和符号表进行交互,其主要作用是从符号表中读取有关标识符种类信息,以确定需要向语法分析器传送的词法单元。
一、词法单元
现在我们就先来看看前面提到的一些专业名词:
- 词法单元:由一个 词法单元名和一个可选的属性 构成。
比如一个特定的关键字,或者代表一个标识符的输入字符序列。
词法单元是语法分析器处理的输入符号。
词素:源程序中的一个字符序列,它和某个词法单元的模式匹配。它被词法分析器识别为该词法单元的一个实例;
模式:它描述了一个词法单元的词素可能具有的形式;
这儿我大致地解释一下这三个概念之间的关系:词法单元指定的是某一类型的事物,用面向对象来说就是,词法单元类(class);词素就是指的是该类的具体实例;而模式就是该类的一个属性,它描述了词素所具有的具体特征。
|
|
并不是说实际就是这个代码,我只是为了便于理解,而进行的类比。下表给出了一些常见的词法单元:
| 词法单元 | 非正式描述 | 词素实例 |
|---|---|---|
| if(关键字) | 字符i,f | if |
| else(关键字) | 字符e,l,s,e | else |
| comparison(比较运算符) | <,>,<=,>=,==… | <=, != |
| id(标识符) | 字母开头的字母/数字串 | pi, printf |
| number(数字) | 数字常量 | 3.1415 |
| literal(字符/串) | 两双引号之间的任何字符 | “hello, world” |
词法单元的大致分类
1)、关键字:每个关键字有一个词法单元;
2)、标识符:一个表示所有标识符的词法单元;
3)、常量:常量词法单元包含的数字和字符串;
4)、运算符:运算法也是一个词法单元,可以是比较运算符,也可以是算术运算符;
5)、标点符号:每一个标点符号有一个词法单元。比如括号等等;
词法单元的属性值
从这里我们可以看出来词法单元表示了一类事物,但是我们如何去区分具体的词素? 词法分析器不仅向语法分析器返回一个词法单元的名字,还会返回一个描述该词法单元的词素属性值。
比如我们声明的一个变量、或者函数时,它作为标识符一类的词法单元。它们更加详细的信息(词素、类型、第一次在源代码中出现的位置)都会保存在符号表中。
因此:
一个标识符的属性值是一个指向符号表中该标识符对应项的指针。
注意,词法单元的属性值是指向符号表项的指针。
二、正则表达式
这一节主要是在讲正则表达式,如果已经熟悉了正则表达式,可以直接跳过阅读词法单元的识别。而且这一节会增加很多概念,也是比较枯燥的。
从前面我们可以感性(直观)知道哪些词素是某一类型的词法单元。为了能够明确地划分不同词素对应的词法单元,我们需要引入正则表达式。
正则表达式是一种用来描述词素模式的重要表示方法。因此正则表达式就描述了特定词素对应的模式。
在词法分析中,最重要的语言上的运算是:并、连接和闭包 运算:
- 并(L|M):得到的串s可能属于L也可能属于M。但只能是其中之一;
- 连接(LM):得到的串s即属于L,也属于M;
- 闭包:闭包分Kleene闭包和正闭包。Kleene闭包是指某一集合的符号重复 0~∞ 多次,可能是空串。正必报不包含重复0次,即不包含空串;
letter_ (letter_ | digit_) *这是一个c语言中标识符的正则表达式。其中用letter_来表示任一字母或者下划线,用digit_表示数位。c语言中标识符必须是必须是以字符开头,包含数字、字符来表示。
优先级
正则表达式中,括号的优先级最高,优先级依次降低:
1)、一元运算符 *;
2)、连接(左结合);
3)、并运算符优先级最低(左结合);
比如正则表达式 (a|b)*,可以表示多个串:
|
|
如上, 可以用一个正则表达式定义的语言叫做正则集合。如果两个正则表达式r和s表示相同的语言,则称 r 和 s 等价r=s 。
例一
c语言中的标识符是由字母、数字和下划线组成的串,下面是c标识符对应语言的正则定义:
|
|
例二
无符号数是形如5280、0.01234、6.336E4或者1.89E-4的串。下面的正则定义给出了这类符号串的精确定义:
|
|
正则表达式的扩展
- 单目后缀运算符+:指的正闭包;
- 单目后缀运算符?:表示出现0个,或者一个;
- 字符类:正则表达式a1 | a2 | a3 |…|an可以缩写为 [a1a2a3…an]。当a1到an形成一个逻辑上连续的序列时,可以写作 [a1 - an];
例三
我们可以使用正则表达式的扩展,来把例一的正则表达式进行改写:
|
|
现在通过正则表达式,我们可以写出对应词法单元对应的模式来。因此下一步要做的就是读取源代码里面的字符流,搭配对应的词法单元的模式,生成对应的词法单元。
三、输入缓冲
很多情况下,我们需要至少向前看一个字符。比如在c语言中,像-、=或者< 这样单字符运算符也有可能是 -> 、== 或者<= 这样的双字符。
在编译原理中会引入一个哨兵标记的双缓冲区方案来处理向前看运算符的问题。
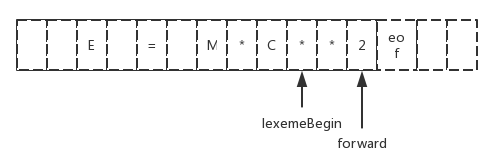
上图中出现的lexemeBegin和forward指针作用分别是:
1)、lexemeBegin:该指针指向当前词素的开始处。当前我们正在匹配某一正则表达式对应模式的词素;
2)、forward:该指针一直向前扫描,直到发现某个模式被匹配为止。
第一步、读取内容到缓冲区中:每次读取缓冲区长度的字符到缓冲区中;
每个输入缓冲区的容量通常是一个磁盘块的大小,比如4096字节。我们在读取的时候就是一次性读取一个缓冲区长度的字符到缓冲区中,以避免频繁的使用读取函数。
当输入文件中的剩余字符不足缓冲区长度的时候,文件的默认会有一个eof(end of file)来表示文件结束。第二步、lexemeBegin和forward指针的移动:使用lexemeBegin指针和forward指针读取指定模式的词素。
一旦确定了下一个词素(下图中的左括号)forward指针将指向该词素 结尾的字符 。词法分析器将这个词素作为某个返回给语法分析器的词法单元的属性值记录下来(在前面我们提过的词法单元分为词法单元名和可选的属性)。
然后lexemeBegin指针移动到 刚刚找到词素之后的第一个字符 。如下图所示:
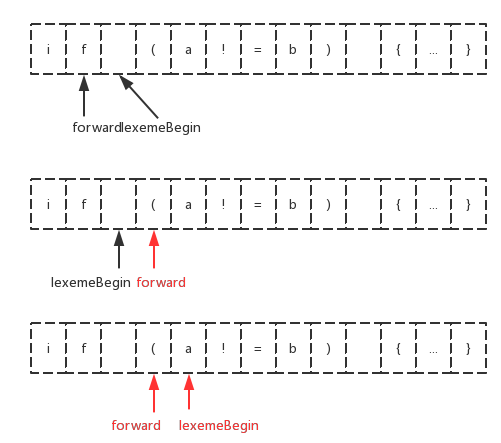
- 第三步、缓冲区的替换:我们在移动forward指针前需要判断当前是否已经到达某个缓冲区的末尾。
如果是,我们需要将新字符读入到另外一个缓冲区中(前面提到的双缓冲区),且将forward指针指向新缓冲区的头部。
哨兵标记
如前面所说,我们在每次移动forward指针时,我们都需要检查是否到达了缓冲区的末尾。如果是的话,我们就需要加载另一个缓冲区。因此在这里我们需要做两次测试:
1)、检查是否到达缓冲区的末尾;
2)、确定读入的字符是什么;
解决这两个问题,我们可以在缓冲区的末尾增加一个“哨兵”,比如eof:
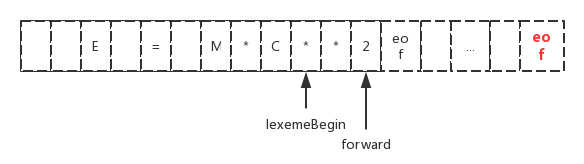
从这儿我们可以知道,对于编译器而言在进行词法分析的时候,需要通过lexemeBegin和forward来扫描缓冲区。如果匹配某一个词素时,比如很长的字符串(比如将一片短篇小说作为常量字符串放到一个变量中)时,那就会出现缓冲区长度不足的情况,因此在日常编码中将长字符串拆分成多个短的字符串。
这其实也算是学习编译原理,有助于提供编程效率的一个例子了。
总结
在前面我们用正则表达式来表示一个模式,现在我们需要通过制定模式来识别对应的词法单元。下面是大部分词法单元,以及对应的模式:
| 词法单元 | 模式 |
|---|---|
| digit | [0-9] |
| digits | digit+ |
| number | digits(.digits)?(E[+-]?digits)? |
| letter | [A-Za-z] |
| id | letter(letter,digit)* |
| if | if |
| then | then |
| else | else |
| relop | <,>,<=,>=,==,!= |
| ws(空白符) | (blank,tab,newline)+ |
由于这块儿markdown解析的问题(加了转义字符之后依然显示有点问题),我将”|”替换为”,”。在理解的时候只需要将”,”更改为”|”即可。
上表中的词法单元ws和其他词法单元不同。当我们识别到ws时,
我们并不将它返回给语法分析器,而是从这个空白符之后的字符开始继续进行词法分析。返回给语法分析器的是下一个词法单元 。
我们从前面的知识了解到,词法分析器通过对应模式识别到词法单元之后,会将词法单元名返回给语法分析器(空白符除外),以及对应词法单元的属性来确定某一特定实例。下表展示了对应词法单元,和对应属性:
| 词素 | 词法单元名字 | 属性值 |
|---|---|---|
| 任何空白符 | - | - |
| if | if | - |
| else | else | - |
| id | id | 指向符号表条目的指针 |
| number | number | 指向符号表条目的指针 |
| < | relop | LT |
| > | relop | GT |
| … | … | … |
| != | relop | NE |
表格里面的relop词法单元,区分其具体实例是通过对应词法单元属性值进行。
这一节主要是了解了词法单元相关知识其中,包括有词法单元、词素和模式。为了能够了解模式,我们又学习了一下正则表达式。下一节则主要是讲解词法单元的识别。