
词法分析——从正则表达式到有穷自动机
自动机在本质上是和状态转换图类似的。但也有一点不同,它们只能对每个可能的输入串简单地回答“是”或者“否”;有穷自动机分为两类:
- 1、不确定的有穷自动机(NFA):其边上的标号没有任何限制,离开一个状态的多条边上可以存在多个相同的符号,也可以是空;
- 2、确定的有穷自动机(DFA):对于每个符号而言,以该符号为标号的边有且只有一条离开该状态。
下面我们就一次来看看不确定的有穷自动机,和确定的有穷自动机。
一、NFA——不确定的有穷自动机
不确定的有穷自动机由下面几个部分组成:
1)、有穷的状态集合,类似于上一节中状态转换表的每一个节点;
2)、一个输入符号集合,可以简单地理解为unicode字符集之类的;
3)、转换函数,类似于状态转换表中的有向箭头一样;
4)、开始状态,或者叫初始状态;
5)、接受状态,也称作终止状态,如下图的双圆圈表示;
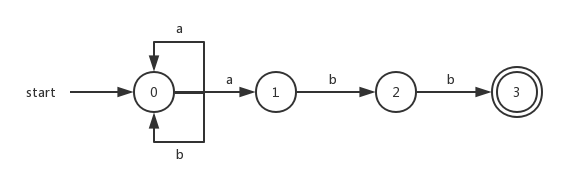
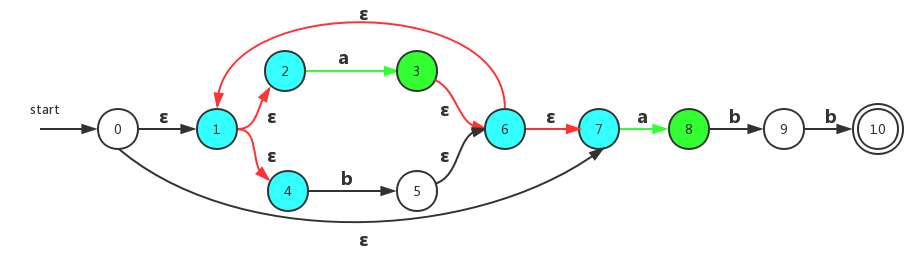
上图是一个能够识别正则表达式 (a|b)*abb的NFA转换图。
转换表和接收串
我们可以将一个NFA表示为一张转换表。表的每一行表示一个状态,表的每一列对应于输入符号和空串。先将上图的NFA转换图转换成为对应的转换表,然后根据转换表再具体说明其中的含义:
| 状态 | a | b | 空字符ε |
|---|---|---|---|
| 0 | {0,1} | {0} | ∅ |
| 1 | ∅ | {2} | ∅ |
| 2 | ∅ | {3} | ∅ |
| 3 | ∅ | ∅ | ∅ |
对于一个给定的状态和给定的转换,其得到的值是NFA转换图中应用对应转换之后得到的状态集合。如果对应的转换没有后续状态,则用符号∅表示。
而自动机在判断是否接收字符串的依据是:存在某条字符序列组成符号串的路径,该路径能够从开始状态到达某个接收状态。我们就说NFA接收这个符号串。比如:
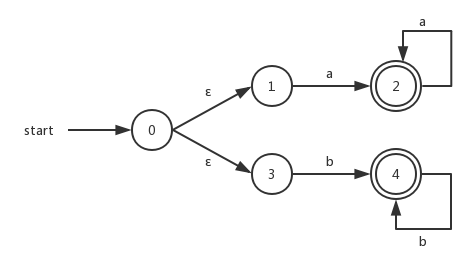
该NFA接收符号串:

即字符串aaa被这个NFA接受。路径中的ε并不会记录在实际的路径中。
二、DFA——确定的有穷自动机
确定的有穷自动机是不确定有穷自动机的特例,它性质如下:
1)、没有输入符号ε;
2)、对于每一个状态s,每一个输入符号a,有且只有一条边离开状态s。
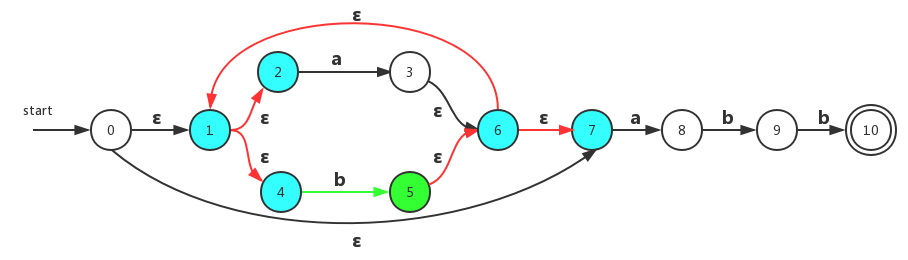
通俗来讲就是指定某个状态,不存在两个或者以上相同的转换存在。比如对于NFA而言,状态0中转换a可以到达两个及其以上不同的状态;而DFA则只能到达一个(有且只有)状态。 比如下面同样是识别(a|b)*abb的DFA转换图:
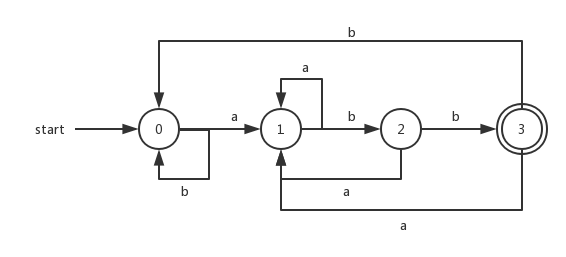
对于给定的输入串ababb,这个DFA的对应状态顺序为:0、1、2、1、2、3。
三、正则表达式、NFA以及DFA之间的关联
这里首先我们将正则表达式转变为接受相同语言的NFA。然后介绍如何将NFA转变为DFA。这样我们就有了一个粗略的方式将正则表达式转换为NFA和DFA的方案。
正则表达构造NFA的规则
通过正则表达式构造NFA主要分为六种情况。在下面每一个情况中,我们都有提出状态i和状态f是否为新状态。指出的意义在于我们需要明确新构建NFA时出现的状态是否为原各个NFA中已有状态,还是需要我们去新增一个状态。比如在连接运算中出现的状态i和f并非新状态,而是已有状态的特殊状态:
规则1、空字符ε表达式;对于表达式ε,构造下面的NFA
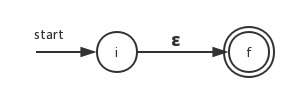
这里i是一个新状态,也是NFA的开始状态;f是另一个新状态,也表示NFA的接受状态规则2、字母表中子表达式;
这里状态i和状态f是新状态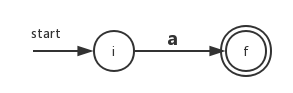
规则3、正则表达式中的并运算;
假设正则表达式s和t对应的NFA为N(s)和N(t),r = s|t的NFA为N(r)。这里状态i和状态f是新状态: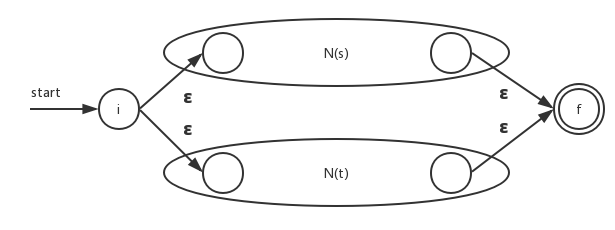
因此从状态i到状态f的任何路径要么只通过N(s),要么只通过N(t)。且离开i或进入f的ε转换都不会改变路径上的标号。因此我们可以判定 N(r)识别 L(r) = L(s) ∪ L(t) 。规则4、正则表达式中的连接运算;
同样的,假设正则表达式s和t对应的NFA为N(s)和N(t),r = st。对应的NFA为:
这个情形下的状态i和状态f并非新引入的状态,而是原有正则表达式s和t中已有的状态。规则5、正则表达式中的闭包运算;
这里假设正则表达式r = s*,N(s)表示正则表达式s对应的NFA。因此闭包运算得到的NFA为:
这里状态i和状态f都是新引入的状态。规则6、括号表达式
r = (s)其NFA是完全相同的;
因此 只有在正则表达式的连接运算和括号存在时,才不会引入新的状态 。N(r)的状态数最多为r中出现的运算符和运算分量总数的两倍。这是因为每一个构造步骤最毒只引入两个新状态。
正则表达式构造NFA实例
现在我们运用上面提到的规则,来将一个正则表达式转换为对应的NFA。将正则表达式转换为NFA的算法是语法制导的,也就是说:
沿着正则表达式的语法分析树 自底向上 递归的进行。
下面关于语法分析树定义部分可以选读,由于会用到很多专业名词,此时大可不必去细究语法分析树,因为对于我来说理解下文并不是必须需要这些知识点。但为了行文的准确性,我将下面要用的语法分析树的定义先列出来。
语法分析树用图形方式展示了从文法的开始符号推导出相应语言中符号串的过程。给定一个上下文无关文法,该文法的语法分析树具有如下形式:
1)、根节点的标号为文法的开始符号(大体上为文法的第一个产生式的首个符号);
2)、每个叶子结点的标号为一个终结符或者空ε(具体字母表中的符号,粗略来看它的叶子结点从左到右组成了最终的正则表达式);
3)、每个内部结点的标号为一个非终结符(可以简单理解为该符号还存在产生式还可以可以推导出终结符号)。
4)、对于产生式A->XYZ,对于X, Y ,Z来说既可以是终结符,也可以是非终结符。
对于正则表达式 (a|b)*abb ,我们构造处对应的语法分析树:
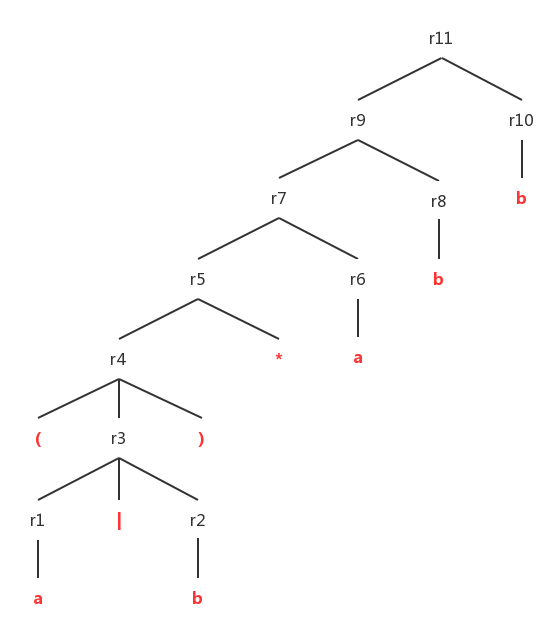
1)、既然是自底向上的,那首先肯定是看子表达式a和b。运用规则1,即可得到两个NFA:
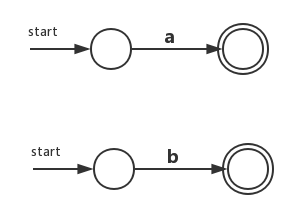
2)、现在的叶子节点为并运算符,此时运用规则3。此时我们需要新引入两个状态,并且原有NFA中的接受状态要变为非接受状态:
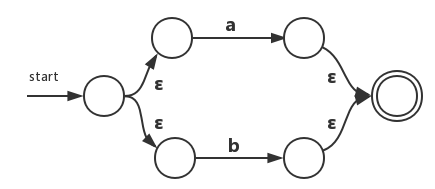
对于带有括号的正则表达式而言,我们从规则6可知,括号运算符不会改变当前的NFA。因此当遇到括号时NFA不改变。
3)、对于闭包运算符来说,同样会引入两个新状态:
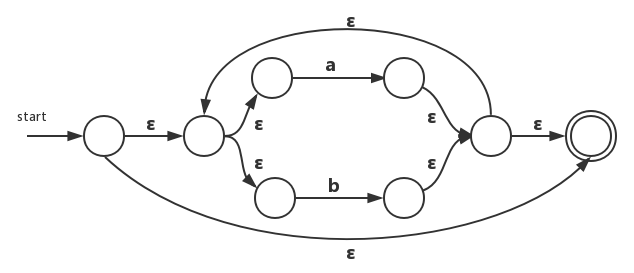
4)、最后是3个连接操作,连接的子表达式分别是a、b、b。因此将它们连接之后得到的最终NFA如下:
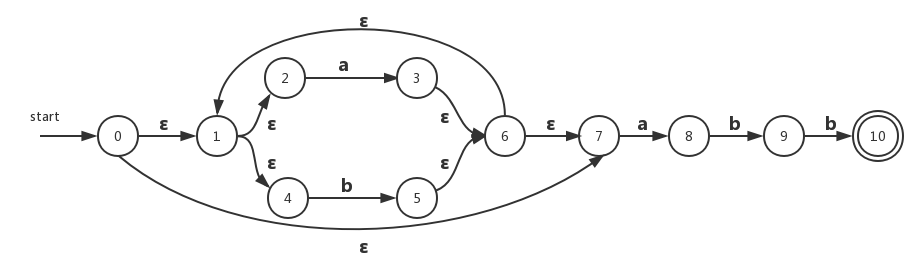
NFA到DFA的转换——子集构造法
现在我们已经能够从正则表达式转换为NFA了,那如果我们要把正则表达式转换为DFA呢?这里先介绍用NFA转换为DFA的方式,后续会将通过抽象语法树搭配firstpos,lastpos和followpos直接从正则表达式构造DFA。现在我们先通过子集构造法来讲NFA转换为DFA。
子集构造法中,我们需要通过NFA为DFA构造转换表。
DFA的每一个状态是一个NFA的状态集合。
DFA的状态是一个集合,该集合里面包含的是对应NFA的状态。
我们在上面看到在将正则表达式构造成NFA时,NFA里面存在很多空转换。所以当务之急是如果正确地处理NFA上面的空转换。下面展示了NFA的状态集合上的相关操作:
| 序号 | 操作 | 解释 |
|---|---|---|
| 1 | ε-closure(s) | 指的是从NFA的状态s开始,可以通过ε转换得到的状态集合 |
| 2 | ε-closure(T) | 指的是集合T中的某个NFA状态,该状态只通过ε转换得到的状态集合 |
| 3 | move(T,a) | 即集合T中的状态通过转换a得到的状态集合 |
假设s0是NFA的开始状态,那么对应DFA的开始状态就是 ε-closure(s0) 。而DFA的接受状态是至少包含NFA接受状态的集合。
我们在上一节得到的NFA,现在我们将该NFA转换为DFA:
1、对于开始状态0,我们使用操作1(上表中序号为1的操作,下文类似),即状态0通过ε空转换可以得到的状态集合为: {0, 1, 2, 3, 7}。
这里有一点需要注意的是:因为路径可以不包含边,所以状态0也是可以从它自身出发经过标号ε到达的状态。
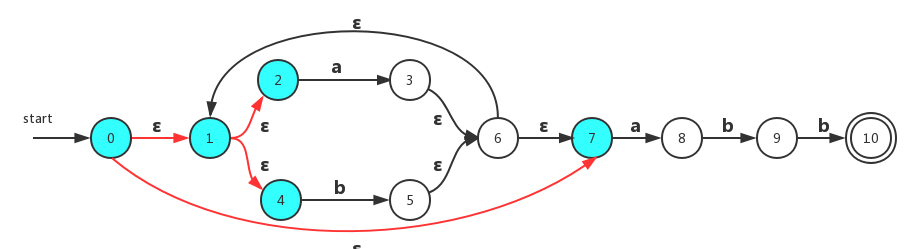
2、我们对第一步得到的集合求转换a的集合。现在我们看状态集合{0, 1, 2, 3, 7}通过转换a(即应用操作3)可以得到的状态集合{3,8}。此时我们对集合{3,8}应用操作2得到的集合为{1, 2, 4, 6, 7}:
在集合{0, 1, 2, 3, 7}里面,只有状态2和状态7可以通过a转换得到的集合是{3, 8}。此时查看状态3通过空转换得到集合为:
a、s3 —ε—> s6 —ε—> s7;
b、s3 —ε—> s6 —ε—> s1 —ε—> s2;
c、s3 —ε—> s6 —ε—> s1 —ε—> s4;
因此最终的集合为 {1,2,3,4,6,7,8}。
3、同样的,我们对第一步得到的集合求转换b的集合。现在我们看状态集合{0, 1, 2, 3, 7}通过转换b可以得到的状态集合{5}。然后集合{5}通过空转换可以得到的集合为{1, 2, 4, 6, 7}
具体的分析和第2步类似。
这样我们对后续出现的每一个状态都执行对应的转换a、转换b。我们可以得到一个状态转换表:
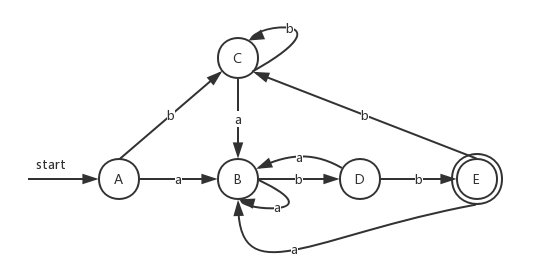
| NFA状态 | DFA状态 | a | b |
|---|---|---|---|
| {0,1,2,4,7} | A | B | C |
| {1,2,3,4,6,7,8} | B | B | D |
| {1,2,4,5,6,7} | C | B | C |
| {1,2,4,5,6,7,9} | D | B | E |
| {1,2,4,5,6,7,10} | E | B | C |
我们前面说过NFA开始状态通过ε转换得到集合为开始状态,因此上表中对应DFA对应的状态为A。而NFA状态集合中包含有接受状态对应DFA的状态E,因此E为DFA的接受状态。对应的DFA如下:
下面是对应算法的伪代码描述。模拟一个NFA的执行(即NFA转换为DFA)
a)、输入部分:
一个以eof结束的输入串x;
一个NFA N,它的开始状态为s0,接受状态为F,转换函数move;
b)、输出:如果NFA N接受符号串x,则返回yes,否则返回no;
|
|
四、词法分析器生成工具的设计
词法分析器的程序包含一个固定模拟自动机的程序(先不指定是NFA,还是DFA)。下图是一个lex程序转换成自动机的结构:
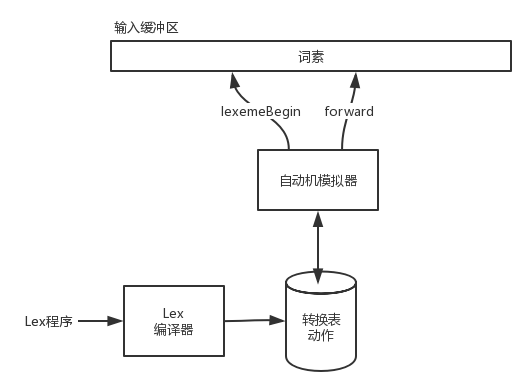
这里提到了前面介绍的几个概念,这儿简要说明一下。输入缓冲区可以让我们依次读入多个字符到缓冲区中(这个大致为4096字节),而不是每读入一个字符就调用一次系统读取命令;词素作为匹配了某个模式词法单元的字符串,比如词素为name词法单元id;指针lexemeBegin指向当前词素的开始位置处;指针forward的作用是一直向前扫描,直到匹配某个模式为止。
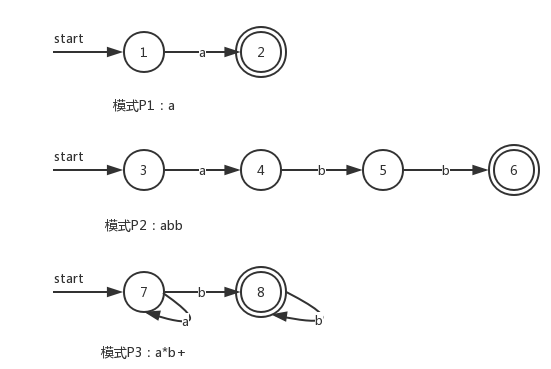
下表中有三个模式,已经对应模式的动作。这个表指明了词法分析器需要的模式,已经匹配到对应模式之后的动作:
| 序号 | 模式 | 动作 |
|---|---|---|
| P1 | a |
A1 |
| P2 | abb |
A2 |
| P3 | a*b+ |
A3 |
这里的动作是指匹配到对应模式之后需要做的相关操作,比如匹配到词法单元id之后的动作是生成对应的标识符,获取对应词法单元并返回给语法分析器;匹配到空白符之后我们将输入回退到非空白符的开头,而且不向语法分析器返回任何词法单元。等等。
上表中满足模式P2和也同时满足模式P3,当出现这种冲突时我们首先选择P2。这是因为在解决冲突时
以先出现的模式为主 (P2先于P3列出)。
下面列出三个模式对应的NFA:
以及将上面三个合并之后得到的NFA:
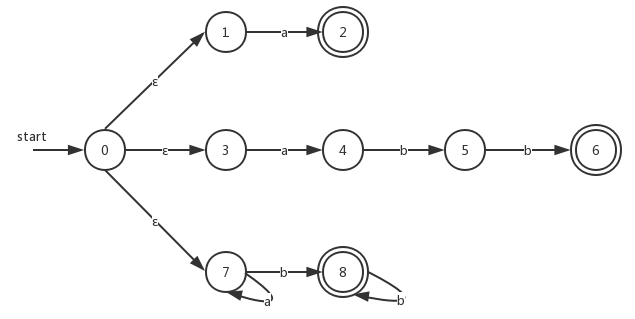
现在如果词法分析器模拟了上图的NFA,那么该分析器必须从它的输入中lexemeBegin指向的位置开始读取输入,并移动forward指针。然后根据子集构造法来获取当前的状态集合。
需要注意的是:这里并不是使用子集构造法将NFA转换为DFA,而只是简单地想知道某一状态集合通过子集构造法之后得到的新的状态集合(不过在下面的“词法分析器使用的DFA”一节会使用该表,该表的第二列就是对应DFA的状态)。
| NFA状态 | 状态编号(DFA状态) | a | b |
|---|---|---|---|
| {0,1,3,7} | A | B | C |
| {2,4,7} | B | D | E |
| {8} | C | ∅ | C |
| {7} | D | D | C |
| {5,8} | E | ∅ | F |
| {6,8} | F | ∅ | C |
在上表中,最终会达到一个没有后续状态的输入点。此时不可能有任何更长的输入前缀使得这个NFA到达某个接受状态,此后的状态将一直为空。比如上表中状态编号为C、E、F之后再继续输入a,那么此时就没有任何的后续状态。
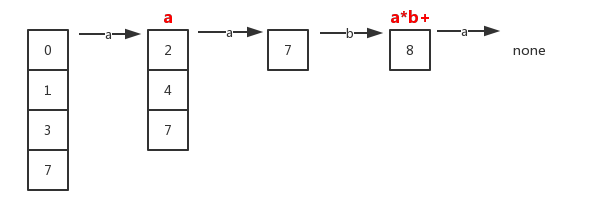
上图中我们的输入字符串以 aaba 开头。当我们在读入第四个符号 a 之后,此时我们处于一个空状态集合中(也可以从上表中第三行得出)。
这时候我们就沿着状态集的顺序往回找,直到找到包含一个或多个接受状态的集合为止 。
如果集合中存在多个接受状态,那么我们就选择模式靠前相对应的接受状态。此时将forward指针移动到词素的末尾,同时执行对应的动作(前面表格中的A1…A3)。
在这里表明输入串aaba被模式 a*b+ 匹配。然后执行对应的动作A3。
词法分析器使用的DFA
根据前面的转换表,我们构造出对应的DFA:
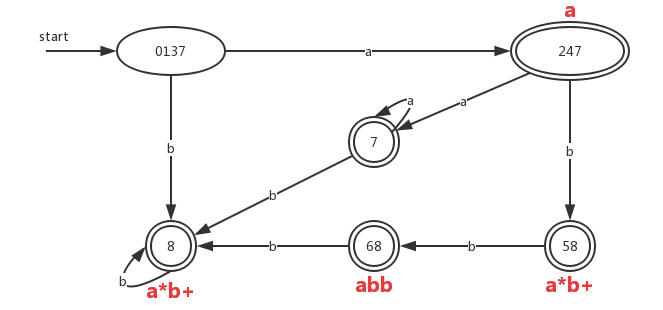
对于状态{6,8}而言有两个接受状态,分别对应于模式 abb 和 ab+ 。由于前一个模式先被列出,因此我们选择 *abb 作为状态{6,8}所关联的模式。
在词法分析器中,使用DFA和使用NFA的方法相似。模拟DFA运行,直到某一点上没有后续状态为止。这种时候我们就沿着顺序往回找,直到找到包含一个或多个接受状态的集合为止。
向前看运算符
有时候为了能够正确地识别某个词法单元的实际词素,我们需要指明 该词法单元模式r1之后必须跟着模式r2 ,因此我们可以将其表示为 “r1/r2“ 。实际上在将r1/r2转换为对应的NFA时,我们把/看成ε(不会去输入中查找/)。 例如:

上图是词法单元IF的模式,在这个模式中我们使用了向前看运算符。状态6表明了关键字IF的出现,因为如果只是单单的空转换之前的模式(r1)将无法准确的识别是关键字if,还是一个带有if前缀的标识符。
当进入了状态6时,我们需要向回扫描到最晚出现的状态2,此时我们找到了对应词法单元的词素。
总结
在本篇文章中,我们认识到了NFA(不确定的有穷自动机)和DFA(确定的有穷自动机),以及它们与状态转换图之间的差异。DFA和NFA最明显的差异莫过于对于每一个状态s,对于同一个输入符号而言有且只有一条离开该状态的边。
其次我们知道了如何通过正则表达式构造NFA,大致的操作有连接、并、闭包和简单的括号操作操作。其中并和闭包操作会引入新状态(使用空转换进行连接)。
然后我们通过子集构造法可以将NFA转换为对应的DFA。其中包括有三种操作,分别是:某一指定状态的空转换;某一指定集合执行空转换;某一指定集合执行特定转换a。通过这三种操作我们构造出NFA对应DFA的转换表。
最后我们了解了一点词法分析器生成工具的设计,以及向前看运算符的作用。