
语法分析——文法的基础概念
前言
在语法分析一章中会出现很多的专业术语,我会在这一节将语法分析涉及到的术语都大致捋一遍。这些专业术语是学习语法分析的必备技能,务必记住并理解,下面我们进入正题。
介绍
语法分析通常用于编译器中。在我们的编译器模型中,语法分析器从词法分析器获得一个词法单元组成的串,并验证这个串可以由源语言的文法(比如上下文无关文法,在后面会详细解释)生成。
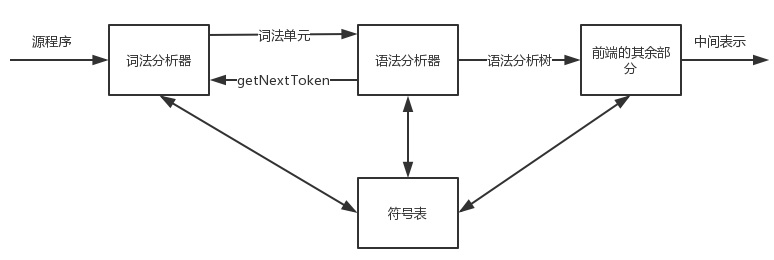
处理文法的语法分析器大体上可以分分为三种类型:通用的、自顶向下的和自底向上的。而编译器中常用的的方法分为自顶向下和自底向上。顾名思义:
1)、自顶向下的方法从语法分析树的根节点开始向底部构造语法分析树;
2)、自底向上则从叶子结点开始,逐渐向根节点方向构造。
这两种分析方法中,语法分析器的输入总是按照从左向右的方式被扫描,每次扫描一个符号。
最高效的自顶向下方法和自底向上方法只能处理某些文法子类,但其中的子类,特别是 LL、LR 它们的表达能力已经足以描述现代程序设计语言大部分的语法构造了。
手工实现的语法分析通常使用LL文法。处理较大的LR文法类的语法分析器通常是使用自动化工具构造得到。
这里的第一个L表示从左向右扫描,第二个的L和R分别表示最左推导和最右推导。有关于推导的概念下面就会展开来说,在前面我们提到了文法,所以现在还是先看看上下文无关文法。
一、上下文无关文法(Context-Free-Grammar)
文法自然地描述了大多数程序设计语言构造的层次化语法结构,比如if-else之类的。一个上下文无关文法由四个元素组成:
- 终结符号:也称为词法单元。词法单元由两个部分组成:名字和属性值。我们常常把这些词法单元名字称为终结符号。因此我们在语法分析中,通常将词法单元和终结符当做一个意思;
- 非终结符号:也称为语法变量,每个非终结符号表示一个终结符号串的集合;
- 产生式:包括产生式头、一个箭头,和一个产生式体;
- 开始符号:指定一个非终结符号为开始符号;
如下图的上下文无关文法:
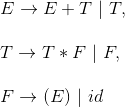
对此,我们需要一些约定来表示不同的符号,以便后续行文方便:
终结符号:
Ⅰ)、小写字母,a、b、c等等;
Ⅱ)、运算符号,比如 + 。 - , * ,/ 之类的;
Ⅲ)、标点符号,比如括号、逗号等等;
Ⅳ)、数字;
Ⅴ)、黑体字符串,比如 id,if。每个这样的字符串表示一个终结符号;
非终结符:
Ⅰ)、大写字母,A、B、C等等;
Ⅱ)、小写,斜体的字符串。比如 expr , stamt 等等;
产生式体:
使用小写的希腊字母,比如α、β、γ表示文法符号串。比如 A -> α,其中A为产生式头部,α为产生式体。
可选体:
具有相同头部的产生式 A -> α1,A -> α2,… ,A -> αk,可以简写为 A -> α1 | α2 | … | αk。在这里我们把α1,α2,αk称作A的可选体。这个可选体概念不太重要,只需要记住相同产生式头部的简写形式即可。
因此,运用前面的约定,我们可以看出这里一共有三个产生式;其中E、T、F为非终结符;+、*、(、)、id为终结符;其中非终结符E为开始符号。
1、推导——最左推导、最右推导
从开始符号出发,每个重写步骤把一个非终结符替换为它的某个产生式的体。比如下面关于非终结符E的文法:
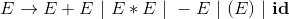
产生式 E --> -E 表明,讲一个E替换为 -E 的过程写作:
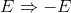
读作 “E推导出-E” 。同样的我们可以按照任意顺序对单个E不断地应用各个产生式,得到一个替换序列,比如:
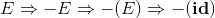
句型:是指推导过程中出现的各种表达式,其中可以包含终结符号,也可以包含非终结符号,当然也有可能是空串;
句子:是不包含非终结符的句型;
一个终结符号串存在于文法G的的语言L(G)中,当且仅当该符号串是文法G的一个句子。可以由文法生成的语言,称为上下文无关语言。
如果两个文法生成相同语言,那么这两个文法是等价的。
比如串 -(id+id) 是文法
的一个句子,这是因为存在推导过程:
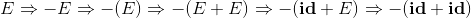
串E、-E、… 、-(id+id) 都是这个文法的句型。在上诉的推导过程中,每一个推导步骤上都需要做两个选择,我们要选择替换掉哪个非终结符号。下面是另外一种推导:
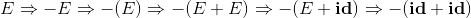
这一个推导和上一个推导稍有不同,我们推导的第四步,选择替换掉的是右边的非终结符。基于此我们的推导有两种推导形式:
最左推导:总是选择每个句型最左边的非终结符号进行替换。如果α => β 是一个推导步骤,且被替换的是α中的最左非终结符号。我们用 α =>lm β (这里lm应该是在推导符号=>的下方,由于不太好书写,因此这里用放在符号右边的形式);
最右推导:总是选择每个句型最右边的非终结符号进行替换。此时我们写作 α =>rm β(同上);
使用最左推导得到的句型称为最左句型。最右推导也被称为 规范推导。
2、语法分析树和推导
语法分析树是推导的图形表示,它过滤掉了推导过程中对非终结符号应用产生式的顺序。语法分析树的每个内部结点表示一个产生式的应用。该内部结点的标号是产生式头中的非终结符号。
这里可以再对语法分析树和词法分析树进行一次对比。上一章词法分析中使用正则表达式构造DFA时提及抽象语法树中每个内部结点为正则表达式中的一个运算符,该内部结点子树的左右子节点分别表示该运算符的运算分量。
比如 -(id+id) 的语法分析树为:
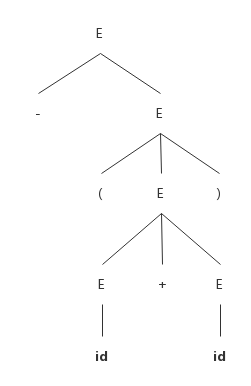
该语法分析树对应的推导过程是上面提到的两个推导:
一颗语法分析树的叶子结点既可以是非终结符号,也可以是终结符号。从左到右排列这些符号就可以得到一个句型,它成为这颗树的 结果。在这里我们从左到右读取每一个叶子结点并排列起来,得到的结果是:- ( id + id ) 。
二义性文法 ,如果一个文法可以为某个句子生成多颗语法分析树,那么它就是二义性的。换句话说,二义性文法就是对同一个句子有多个最左推导或者最右推导的文法。
到这儿,我们可以先看一个例子。
例一
对于文法 ,有一串aabbab。尝试写出最左推导和最右推导出该的语法分析树。
最左推导语法分析树:
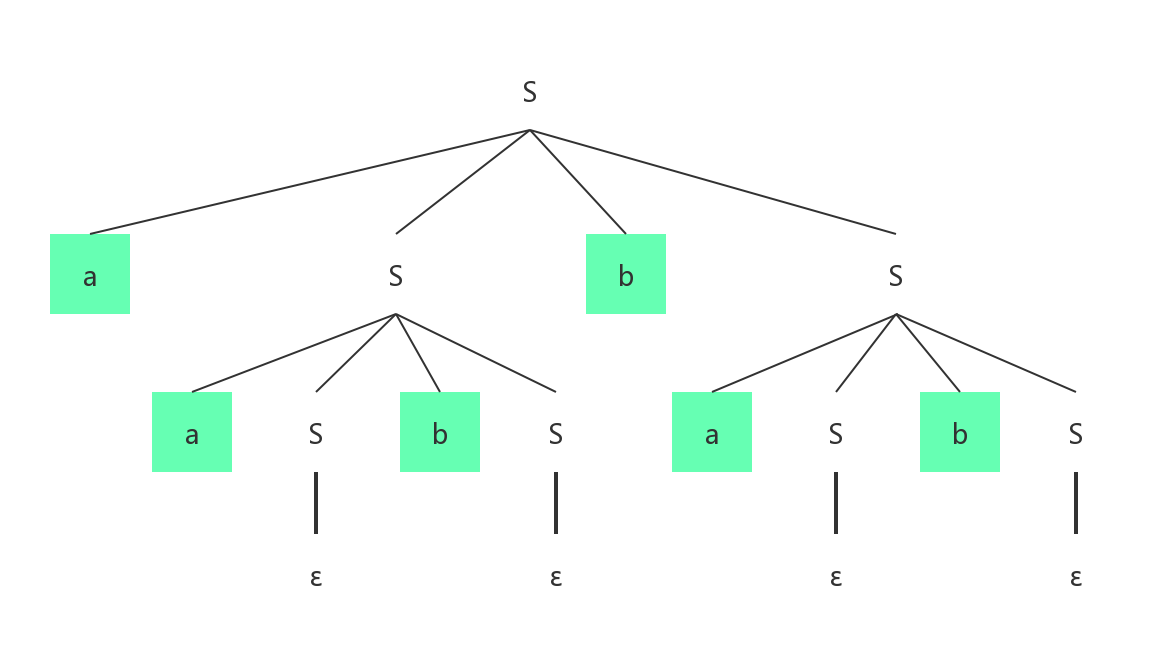
最右推导语法分析树:
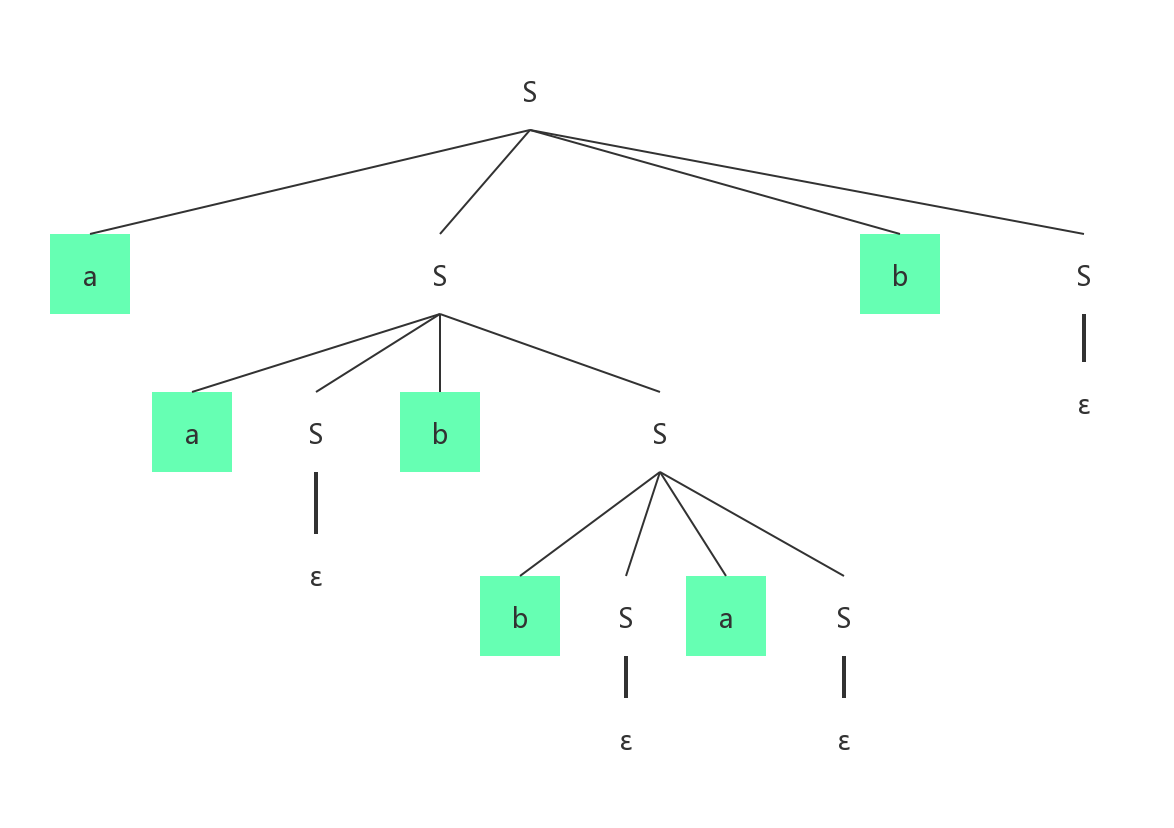
从语法分析的结构,我们不难看出来该文法是二义性文法。
3、上下文无关文法和正则表达式
文法是比正则表达式表达能力更强的表示方法。即每个可以使用正则表达式描述的构造都可以使用文法来描述,但反之则不成立。我们可以根据正则表达式构造出对应的文法,下面则是从正则表达式构造对应文法的大致步骤。如下:
1)、对于NFA的每个状态i,创建一个非终结符Ai;
2)、如果状态i有一个在输入a上到达状态j的转换,则加入产生式 如果状态i在输入 ε 上到达状态j,则加入产生式 ;
3)、如果i是一个接受状态,则加入产生式 ;
4)、如果i是自动机的开始状态,令 Ai为所得文法的开始符号;
比如正则表达式 $(a|b)^{*}abb$ ,它对应的DFA为:
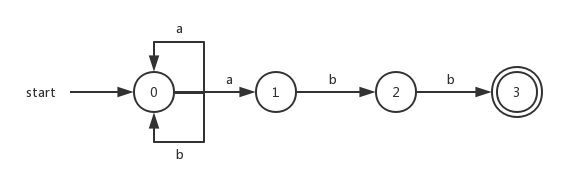
从上面步骤我们可以得到一共有4个状态,因此对于对应文法则有4个非终结符,分别为 。根据上图的转换我们得到文法为:
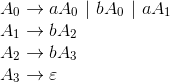
二、设计文法
如果前面看到的,任何能够使用正则表达式描述的东西都可以使用文法来描述。因此在这儿来列举4点关于正则表达式和文法的异同:
1)、将一个语言的语法结构分为词法和非词法两部分可以很方便地将编译器前端模块化,将前端分解为大小合适的组件;
2)、一个语言的词法规则通常很简单,我们不需要使用像文法这样功能强大的表示方法来描述这些规则;
3)、和文法相比,正则表达式通常更加简洁,并且更容易理解;
4)、根据正则表达式自动构造得到的词法分析器效率要高于文法得到的分析器;
根据上诉4点来说明,既然正则表达式都可以使用文法来描述,而在词法分析中我们依然选择了正则表达式来描述词法单元;
正则表达式更适合描述标识符、常量、关键字、空白这样的语言构造的结构;文法更适合描述嵌套结构,比如if-else之类的;
1、左递归
左递归是指 产生式体的最左边符号和产生式头部的非终结符号相同 。对于产生式
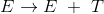
产生式的头部是E,同时E也是产生式体的最左边的非终结符号,因此该推导将会被将被递归调用。
同样的,右递归也就是指的产生式头部的非终结符号和产生式体最右边的终结符相同的情况。
该文法无法用于自顶向下的语法分析中,这是因为自顶向下的语法分析是基于LL文法的。而对于LL文法来说,第一个L指的是从左到右扫描语法分析树的一层的每个结点,遇到非终结符则应用对应非终结符的产生式。第二个L指的是最左推导。前面我们已经知道了最左推导,即每一次替换掉产生式最左边的非终结符,因此这也就和左递归的定义吻合了。关于更详细的自顶向下的语法分析将在后面进行详细讲解。
既然存在左递归,那么消除左递归肯定是有必要的。
消除立即左递归:
比如存在立即左递归的产生式:
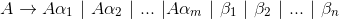
其中 $\beta _{i}$ 都不以A开头。因此我们可以用下面的技术来消除立即左递归:
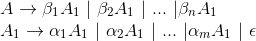
需要特别注意的是:第二个产生式到空串的产生式 。非终结符号A生成的串和替换之前生成的串一样,但不再是左递归的。这个过程消除了所有$A$和$A_{1}$产生式相关联的左递归。
比如我们对文法
应用消除立即左递归的技术上面文法的左递归,得到的结果为:
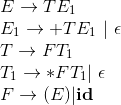
消除一般左递归
但并不是所有的文法都是立即左递归的,有可能是经过多次推导之后才发现递归的情形。比如下面的文法就不是立即左递归:
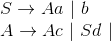
对于推导
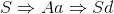
可以看出非终结符号S是左递归的,但它并不是立即左递归。那么对于这种情况的左递归如何消除呢?
1)、首先将文法的所有非终结符,从开始符号按出现顺序,依次对它们进行编号为A1, A2, A3, …,An;
2)、从A1开始依次读取每一个非终结符到An,我们称作Ai;
同时又从A1开始读取非终结符号到Ai-1,我们称作Aj 。如果存在形如 那我们就将其替换为产生式组:
这样我们就可以尽最大的可能构造立即左递归了。
3)、如果此时存在立即左递归,则使用上面提到的消除立即左递归的方式来消除;
下面我用C++写了一个简单地消除左递归的例子:
|
|
比如我们有带左递归的产生式集合:
现在我们可以使用上诉的C++代码来帮我们消除左递归:
|
|
最后的输出结果如下:
|
|
解释一下,这里的非终结符号B是A的产生式出现左递归之后,引入的非终结符。
2、提取左公因子
提取左公因子可以适用于预测分析技术或自顶向下分析技术的文法。当我们不清楚应该在两个产生中如何选择的时候,我们可以通过改写产生式来推后这个决定,当我们有足够的信息时再做出正确地决定。
比如有产生式 ,是A的两个产生式,并且产生式体开头都是从 α 推导得到的一个非空串。那么这时候我们就不清楚是产生式 还是以产生式 进行展开。
然后我们可以将A展开为 ,从而延迟要做出决定的时刻,原来的产生式就变为了:
总结一下上面提到的内容:对于每个非终结符号A,找出他的两个或多个选项之间的最长公共前缀 α。如果 α 不为空,即存在一个非平凡的公共前缀,那么将所有A的产生式
替换为
其中 γ 表示所有不以 α 开头的产生式; 是一个新的非终结符号。不断地应用这个转换,直到每个非终结符号的任意两个产生式体都没有公共前缀为止。
3、非上下文无关语言的构造
在常见的程序设计语言中,存在少量无法文法描述的语法构造。在C或者Java的文法不区分由不同字符串组成的标识符。所有的标识符在文法中都被表示为像 id 这样的词法单元。在这些语言的编译器中,标识符是否先声明后使用是在语义分析阶段检查的 。
三、总结
在本篇文章中,介绍了一大堆的概念。比如上下文无关文法里面的产生式、终结符、非终结符,还有开始符号等等;然后我们接触到了推导的概念,推导又分为最左推导和最右推导。我们根据这两种推导,我们可以构造出对应语法分析树;语法分析树的所有叶子结点从左到右拼起来之后,得到的就是对应产生式文法的句子。而中间过程中出现的则成为句型;
而且,我们也了解到如何通过正则表达式来构造对应的上下文无关文法。大致的过程是根据正则表达式,我们可以根据词法分析一章的知识来构造一个NFA(根据连接、并、闭包运算对应的状态转换图)。我们根据NFA的状态数对应非终结符号,具体转换规则都已经详细列在了上面;
在构造文法的过程中,我们遇到左递归的情况。因此我们需要知道如何去消除立即左递归,和左递归。详细的消除方法在上面用C++语法已列出;最后我们还了解了提取左公因子的方法,当我们不清楚应该如何选择产生式,推迟这个时机,待我们有足够信息做出正确选择之前。
下一篇文章,我们将会去看看自顶向下的语法分析技术。