
细看objc-weak源码
本文不看其他,只专注于weak的内部结构实现细节和源码解读,看了网上很多的文章都是贴上一篇open source里面的代码,并没有对实现细节进行解释。所以在这篇文章中,主要分为
weak_entry_t、weak_table_t的源码解析,weak_entry_t和weak_table_t的相互关系,以及对应的操作函数。
下文的主要是基于两个对象来说的,一个是被引用的对象,一个是弱引用变量(也就是源代码中大量出现的指向指针的指针)。
我说一下我源码阅读的习惯,先把目光放在头文件中,因为头文件能够给我们一个整体基础结构。弄清楚具体的结构之后,然后再跳到实现文件中去看具体的实现细节。
先交代一下我的编译环境和源代码版本:
编译环境:
Apple LLVM version 9.1.0 (clang-902.0.39.1)
Target: x86_64-apple-darwin17.5.0
Thread model: posix
InstalledDir: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin
源代码版本:
objc4-723
头文件类关系和结构分析
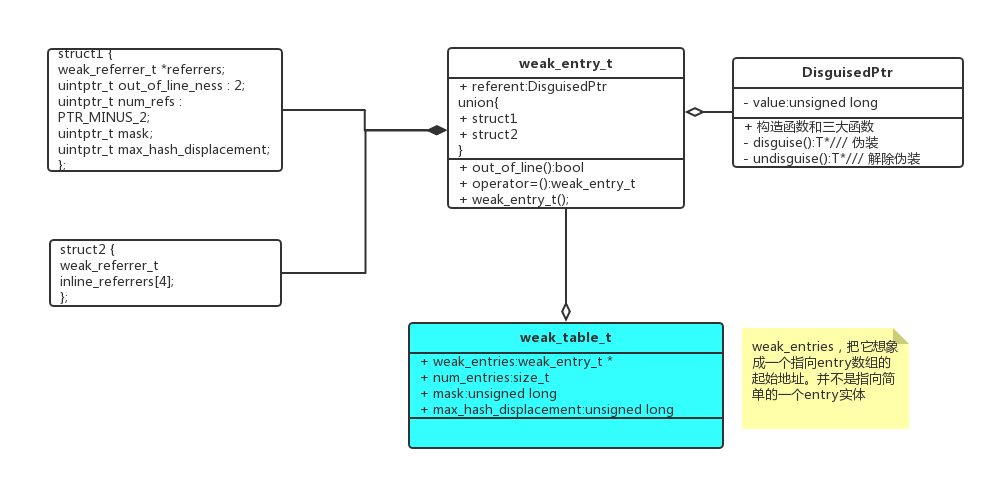
我先根据头文件画一个基本的UML类图:
DisguisedPtr模板类
先将视线放在weak_entry_t上面,结构weak_entry_t的第一个成员变量是referent,它是一个DisguisedPtr类模板实例化之后的变量(点开前面的链接吧,不然我讲不清楚,不然你会骂我的),这个成员其实就是保存被引用的对象。
DisguisedPtr类里面看起来这个类并不复杂,有一个uintptr_t类型的成员变量,由此DisguisedPtr类的对象所占用的内存空间大小也应该为8字节。
public下面主要是构造函数加三大函数中的两个:重载复制运算符,赋值构造函数;由于该类里面并没有涉及到动态new指针变量,所以其析构函数便使用了默认析构函数。除此之外还重载一些其他的操作符。主要看一下私有的两个成员函数:
|
|
其中disguise函数是将指针变量强转为uintptr_t的整形变量,具体怎么伪装呢?就是把该指针指向的内存地址(16进制数据比如:0x7ffeefbff4e8)强制转换为无符号长整型的十进制数据。由于其类型是无符号长整型,因此取负数是数据溢出之后取该类型取值范围内较大的长整型值达到伪装的效果(也就是不好去找到原内存地址)。
|
|
其作用在源文件的注释中也说了,我通俗总结是:对那些比如leak这种内存检测工具进行伪装,然后这些检测工具可能就不好去跟踪被引用的对象。
weak_entry_t
现在来看一下union的具体内存分布细节,怎么来解释这个问题呢?奉上objc-weak.h的源码,打开源码配合文章来看。
|
|
首先要有一个概念,union里面的多个成员是共享同一且相同大小的内存空间,在strcut1结构成员中算出其总共所占内存大小为64*4,也就是32个字节。其中我的机器是64位机,我的编译器对于指针类型所占内存大小的ABI实现为64位,而无符号长整型占用的内存大小也为64位。多说一句,在C++中结构和类的内存存储区域好像都是在堆上面,由低地址向高地址生长。
基于此来画出inline_referrers和上面第一个结构大致的内存分布样式(关于inline_referrers的元素类型模板类DisguisedPtr所占内存大小在上面讲DisguisedPtr类时提到了):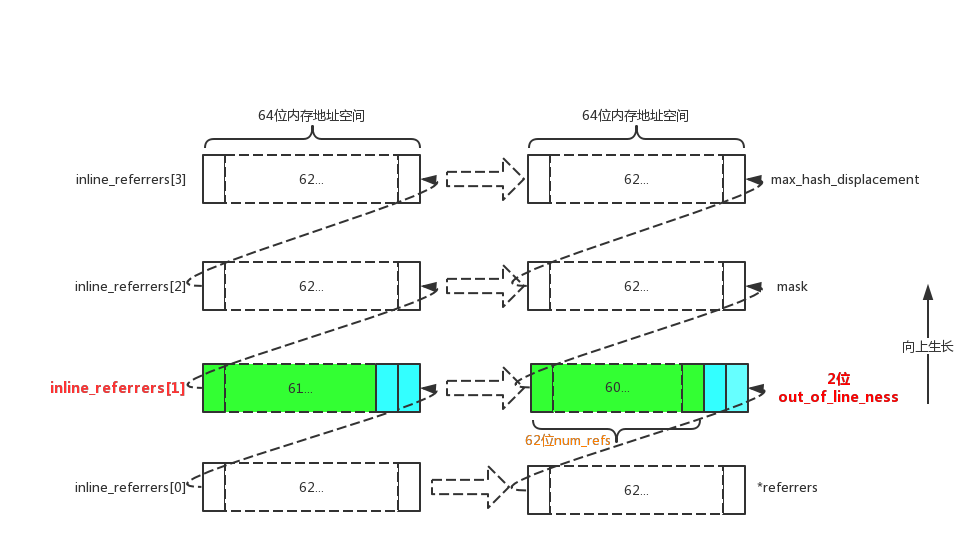
在源码中注释也说了:
|
|
out_of_line_ness是和inline_referrers[1]的低2位是等同的,out_of_line_ness和num_refs使用了位段,一共占用64位(2位和62位)。由于此时已经是结构内存对齐了,所以下一个结构成员mask的内存地址就刚好换行。
上面还提到的0x0b10,它应该是经过DisguisedPtr伪装之后得到的值,并不是实际的等于0b10,一个只占两位内存空间的,怎么也存储不了16位的数据。out_of_line_ness == 0b10是标记使用out-of-line的状态。关于这个0b10我没有想清楚它的由来,有知道的同学麻烦告知于我!!!
继续来看该结构的构造函数:
|
|
在创建weak_entry_t实例的时候,默认是使用inline_referrers的方式来管理对象引用的,并把其余的位上的数据清空。out_of_line_ness用来判断使用out_of_line的方式来进行引用管理,这个out_of_line_ness的值主要是依据于被引用的对象,其引用变量的个数决定的,具体的逻辑在下文会讲到。
再看看struct1的referrers成员,看起来是一个指针变量,更具体的说是存储的引用变量数组的起始地址,而这些引用变量指针指向的地址被DisguisedPtr进行了伪装。
到这里我把weak_entry_t的内存分布讲了一遍(具体的含义在上面代码块中的注释里),然后下面来看一下weak_table_t。
weak_table_t
weak_table_t在头文件中看不出什么特别的内容,但是从源码中可以看出,应该是一个基于C的结构,没有使用C++中结构独有的特性。
|
|
同样的,其weak_entries成员也应该是一个数组,存储着weak_entry_t变量的指针。针对该结构头文件中公开的操作函数有:
|
|
这看不了什么具体的内容,所以针对头文件的解读就到这里。下面去实现文件中看看具体的实现,看看网上为什么都在说的基于Hash表的一个存储结构。源码地址,老规矩,打开这个网页对照着源码来看。
objc-weak具体实现细节
首先看两个hash函数:
|
|
它们会根据对象的指针(不管是指针还是指向指针的指针)调用一个fast-hash函数来生成一个key,其原理是基于fast_hash,而这个key的作用目前我们无从得知。
grow_refs_and_insert函数
继续看源码,下面主要来看看一个很重要的函数:
|
|
由于基于C的数组其实都是定长的,为了能够动态地增加新元素就需要不断地去申请新的内存空间,并且还要是连续的内存地址(要是不连续的地址就去使用链表的方式,但是链表的索引明显弱于数组的)。正是因为新动态申请的连续内存空间,这就需要把老数据复制过来,并把需要新增的数据也追加进去,最后释放掉原内存空间: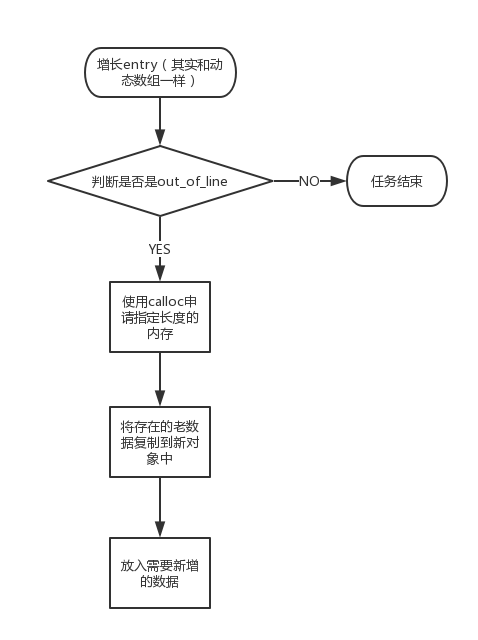
它其实和C++里面的动态数组的原理一样,为了不频繁地去申请(calloc)新的空间和频繁地数据移动。所以每次2倍增长来增加weak_entry_t的长度。为什么说是C++里面动态数组的做法,在《数据结构与算法实现-C++描述》里有提及这些内容。
append_referrer和remove_referrer
在grow_refs_and_insert函数中调用了append_referrer函数,这个函数很明显是做插入操作的,默认使用inline的方式来增加新增的weak引用,如果使用inline的方式失败了,则是以outline的方式,并申请对应的存储空间,把entry->referrers指向新申请的内存地址,把inline_referrers数组里的数据拷贝到new_referrers中,其源码如下:
|
|
从这里就可以看出,当被引用对象的弱引用referrers个数小于WEAK_INLINE_COUNT时,其entry里面是以inline小数组方式来存储这些弱引用变量的,只有当inline_referrers全部装满之后,该entry out_of_line被设置为REFERRERS_OUT_OF_LINE,后续如若有变量继续引用该对象则是以outline的方式存储的。
union是在被引用变量的referrers个数小于等于WEAK_INLINE_COUNT时,使用inline数组的内存表现形式;当referrers个数超过了WEAK_INLINE_COUNT则以struct1的内存表现形式!
由于使用inline的方式是使用小数组的方式,但是针对弱引用对象过多,那么它的存取性能就是考虑的一个重点。而散列是一种用于以常数平均时间执行插入、删除和查找的技术。
下面这个过程我不是很确定,如有不同的建议希望指出。
|
|
begin是通过引用new_referrer调用散列函数获取一个散列值,这个散列值就是散列表中的元素查找自己所在散列槽的key。
从源码可以看出,通过散列值查找元素对应散列槽的方式好像是使用了线性探测法。简化上面的代码,配合下方这图来看一下把new_referrer指针查找正确index的过程: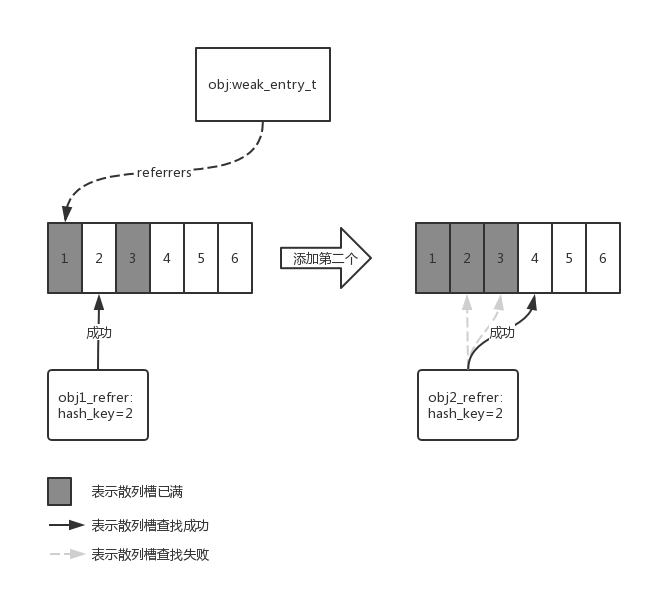
如上图,假设使用w_hash_pointer获取到的key为2,obj1成功插入到散列槽2中,obj2使用w_hash_pointer获取到的key也为2,此时散列槽2已经放入了obj1,那么只有正向地去寻找下一个散列槽,如果为空则放入obj2。
回到源码中,在求begin值的时候。把hash值和entry->mask做了按位与的操作,但是这里为什么要对entry->mask做一次按位与操作呢?
entry->mask存储着weak_entry_t的referrers数组大小,这样做能保证所得的散列值是小于当前数组的出界的,因为大于referrers数组大小对应的二进制位的高位全部被置为0,从而避免出现数组越界带来的问题。
关于出界和入界的概念,可以在《C陷阱与缺陷》中关于一个介绍for循环越界导致的死循环一节,具体的记得不是很清楚了。针对出界这个概念还是蛮重要的,老板们可以去看一看。remove_referrer和append_referrer在源码上来看基本没有什么区别,区别只不过是一个赋值,一个置空而已。
weak_table_t的扩容和减容
针对weak_table_t的扩容和减容源码相对来说比较简单,限于篇幅我没有提供对应的代码,所以在看的时候还麻烦自己打开上面提到的源码地址对照来看。
在源码中主要提供了如下函数:
weak_entry_insert;
函数weak_entry_insert和上一节提到的append_referrer是类似的,weak_table_t的内部实现同样也是使用散列表的方式来管理所有的entry变量的。只是weak_entry_insert没有去尝试inline的那一步。weak_resize;
函数weak_resize和上面提到的grow_refs_and_insert函数类似,在调整大小时,都是创建一个新尺寸大小的内存空间,然后将原内存空间的数据移动到新的内存空间。weak_resize只有移动老数据,没有新数据的添加!最后释放掉原内存。weak_grow_maybe;
函数weak_grow_maybe是在原weak_table的entry数量大于了weak_table数组容量的3/4时,便调用weak_resize去扩充容量到原数组容量的2倍。weak_compact_maybe;
函数weak_compact_maybe是用来收缩容量的,当数组的容量内大部分都为空的话,则减容。
|
|
- weak_entry_remove;
函数weak_entry_remove用来weak_table_t的entries里对应的entry
|
|
sizeof(*entry)获取到了weak_entry_t所占用的内存大小,使用bzero是将该内存段全部置为0,使用bzero而不使用memset影响并不大,使用memset需要多传入一个参数来确定需要重置的值。在《Unix网络编程》里创建sockaddr_in结构变量时,把对应内存空间数据清空用到了bzero,并讲了一下和memset的区别,具体内容可以去看看这本书。
头文件暴露的四个函数
在头文件中暴露了四个外部可用的函数,分别是:weak_register_no_lock、weak_unregister_no_lock、weak_is_registered_no_lock和weak_clear_no_lock,根据注释来看主要是针对weak_table_t的添加、删除和清空数据等操作。在这里以下面的代码为基础来讲解:
|
|
下面再来具体看看这几个函数在干什么?weak_register_no_lock源代码中提出,注册一个新的键值对,如果新的弱对象不存在则去新创建一个对应的entry。
|
|
如果被弱引用指向的对象(obj)是isTaggedPointer,这里便不做相关操作,直接返回弱引用指向的对象(obj)。
关于什么是Tagged Pointer,后面我再去细看一下里面的源码。从这里的源码可以看出,如果是TaggedPointer就不做后续操作,因为指针并没有指向真正的内存地址,返回的值则是被引用对象自身。
|
|
如果存在对应的entry则直接调用append_referrer进行插入。如果不存在,则调用weak_entry_t的构造函数创建一个新的对象,并查看是否需要针对weak_table进行扩容,将新的entry插入到weak_table中。下图是一个为对象增加弱引用,并将引用添加到weak_table中的简易流程: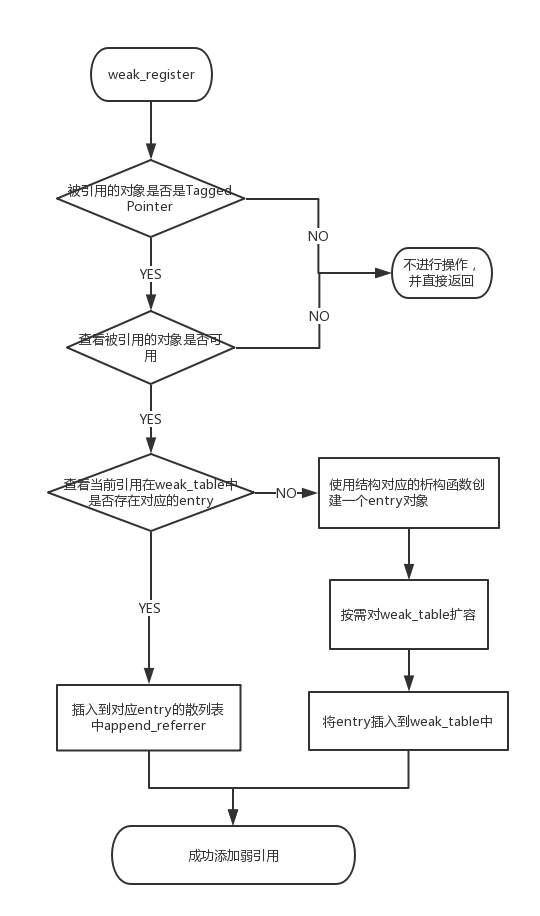
现在来看一下weak_unregister_no_lock函数,针对weak_table的移除,必须确保entry已经存在于weak_table中,才会去进行后续的操作,同样把对应的流程图画出来: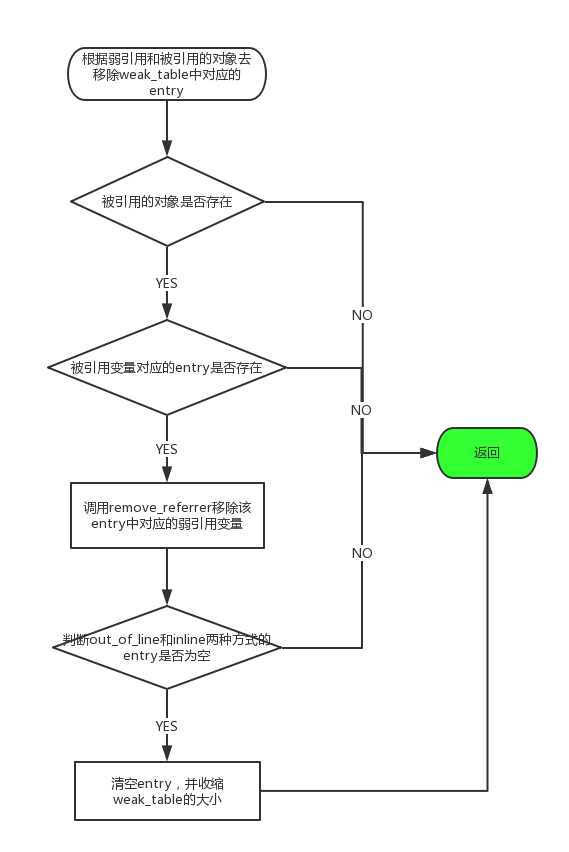
最后两个函数是一个是debug状态下用于判断某一entry是否存在于weak_table中,另一个函数则是对特定的被弱引用的对象(obj)的所有引用做清楚操作。
结语
到这里objc-weak应该算是讲清楚了(天知道我的表达能力怎么样。。。),最后我从外层结构到内层结构来一一总结下:
1、weak_table可以存储多个entry,而且它会根据其散列表中entry的个数来伸缩其所占内存大小;
2、一个entry表示的是一个被弱引用的对象(上文提到的obj),该变量可以被多个变量弱引用(refer)。所以entry也存在一个散列表,其用来存储对应的弱引用变量的引用。也就是前面源码里面提到的指向指针的指针。
3、entry的out_of_line_ness只有在弱引用变量大于WEAK_INLINE_COUNT时才会置为REFERRERS_OUT_OF_LINE。也就是只有在这时候union才会使用struct1结构内存布局。
4、还有就是out_of_line_ness == 0b10没有看懂。。。